
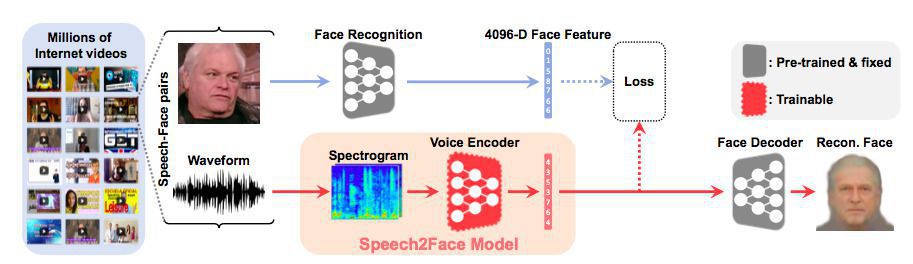
Американські розробники представили нейромережеву модель Speech2Face. Навчена на кількох мільйонах відео, ця модель вміє відтворювати за спектрограмою мови людини зразкове зображення її обличчя, ґрунтуючись на трьох основних параметрах: стать, раса і вік.
За голосом людини можна з різною точністю визначити деякі її особливості: легко можна визначити стать, трохи складніше (але все одно можливо) — вік, а наявність акценту дає загальне уявлення про національність. В результаті цього можна приблизно уявити, як виглядає людина, але це уявлення не буде достатньо точним, інформує Ukr.Media.

Вчені з Массачусетського технологічного інституту за участю Техена О (Tae-Hyun Oh) вирішили перевірити, чи можна точно відновити зовнішність людини за її голосом з допомогою машинного навчання. Для навчання нейромережі вони використовували датасет AVSpeech, що складається з більше мільйона коротких відео більше ста тисяч різних людей: кожне відео в базі даних поділене на аудіо — та відеодорожку.
Архітектура натренованої нейромережі влаштована таким чином. Спочатку попередньо натренований алгоритм VGG-Face (раніше його використовували для створення моделі, яка вміє визначати сексуальну орієнтацію людини — за умови її бінарности) використовує особливості обличчя людини з кадру на відео для створення зображення обличчя людини в анфас з нейтральним виразом. Інша частина алгоритму відтворює з аудіодоріжки використаного відео (невеликого фрагмента — від 3 до 6 секунд) спектрограму мови і, використовуючи результати з паралельної нейромережі, яка генерує зображення обличчя, дає на вихід зразкове зображення обличчя людини, яка розмовляє на відео.
Точність розробленого алгоритму оцінили за трьома демографічними показниками: вчені порівняли стать, приблизний вік і расу оригінального зображення людини з відео і зображення, відновленого на основі голосу. Незважаючи на те, що авторам вдалося домогтися успіхів у відновленні зображень деяких людей за відео, об’єктивні метрики показують недосконалість розробленої моделі. Зокрема, модель добре вгадує стать людини, але рідко може визначити вік з точністю до десяти років, а також найкраще «малює» людей з європеоїдною та азіатською зовнішністю.
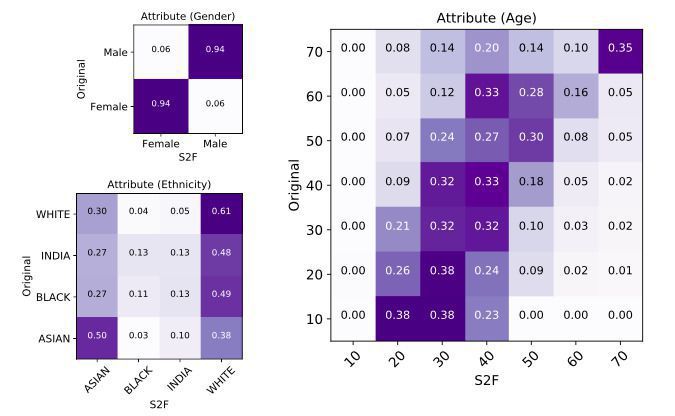
Дослідники відзначили, що метою їх роботи не було точне відновлення зовнішності людини за її голосу; вони зосередилися саме на виділенні і точності деяких важливих параметрів: статі, віку та етнічної приналежності. Саме тому точно показати по голосу, як виглядає людина, поки що не можна: при цьому певних параметрів вистачить для того, щоб створювати, наприклад, анімаційні аватари людини за її голосом. Також вчені відзначають, що їх робота носить також дослідницьку користь: генерація цілих облич на основі голосу допоможе краще вивчити кореляцію із зовнішністю.
Минулого тижня інший алгоритм, який виділяє особливості обличчя з зображення людини, використовували для того, щоб перетворити статичні зображення (не тільки фотографії, але і картини) в анімовані зображення.



















